Fundamentals of Data Visualizations를 공부한 내용입니다.
색을 쓰는데는 3가지 이유가 있다:
- 구별하기 위해
- 대표하기 위해
- 강조하기 위해
이유를 가지고 차트를 그려보자!
1. 구별하기 위한 색: Qualitative Color Scale '다 다른 데이터네'
일단, 구별한다는 것은 순서가 없는 아이템에게 쓰인다 ex 나라 이름. 이 팔레트 색상은 톤은 일정하고 색상만 다르다. 톤이 일정해야 어느 한 색상이 튀지 않기 때문이다. 한 마디로, 톤온톤은 비추한다는 것이다. (반대로 어느 한 데이터만 튀어야 되면, 전략적으로 그 데이터만 다른 톤 ex. 비비드 톤을 줄 수 있을 듯? 데이터 자체/진실을 왜곡시키는 것은 아니니까.)

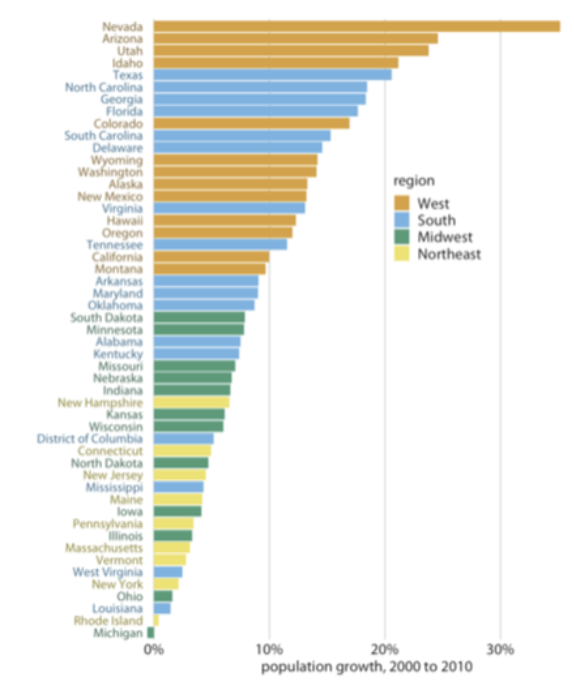

2. 대표하기 위한 색: Sequential Color Scale, Diverging Color Scale
순서가 있는 데이터는 보통 하나의 색 스케일 안에서 움직인다 (톤온톤). 짙은 색은 큰 데이터 값, 옅은 색은 작은 데이터 값. 보통은 single hue (dark A색 to light A색)이지만, 차이를 강조하고 싶을 때엔 multiple hue (dark A색 to light B색)일 수도 있다. Multiple hue사용시 dark 색은, 색 그 자체가 어두운 색에 속한 색이어야 한다 ex. dark yellow (X). 만약에 데이터 값이 0%-100%, -50부터 50 등 양끝과 중간이 명확하게 존재한다면 diverging color scale을 쓰는게 좋다. 양끝 값이 특정 색을 차지하고, 따라서 중간에 해당하는 색상은 대부분 흰색에 가깝다.
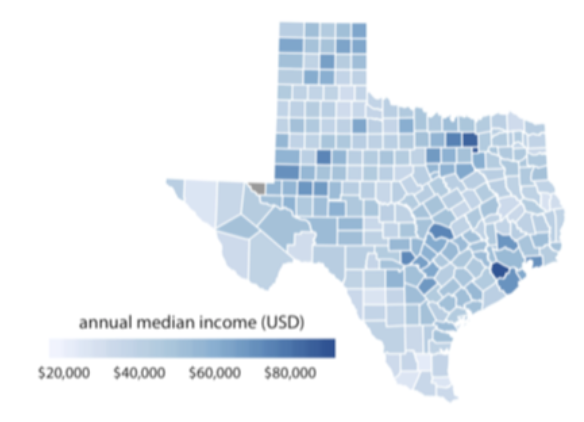
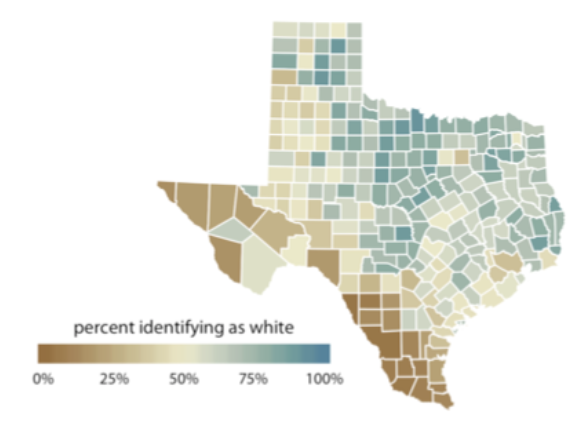

3. 강조하기 위한 색: Accent Color Scale on key information
Accent color scales contain subdued colors and a matching set(즉 톤은 같은) of stronger, darker, and more saturated colors. 인터렉션 시 mouse hover에 자주 사용된다.
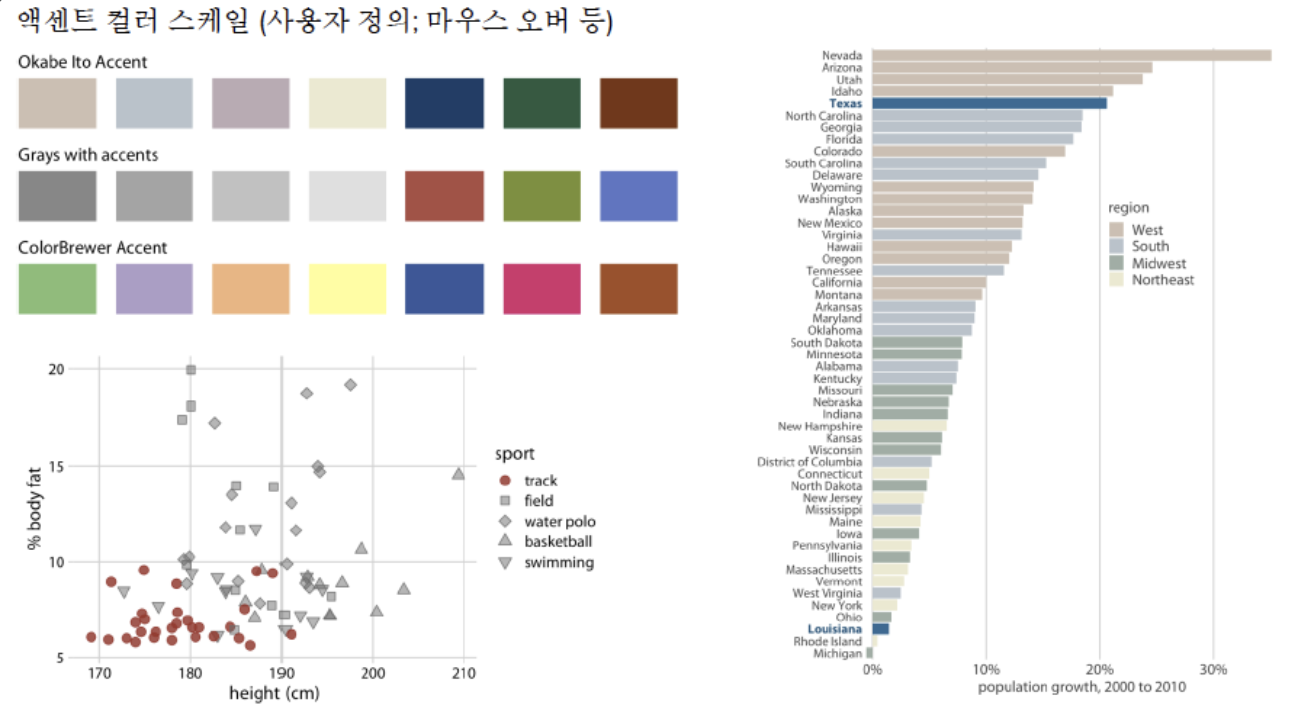


이전 글:
2021.09.16 - [data] - 데이터시각화 개론 - Fundamentals of Data Visualization 1/3
데이터시각화 개론 - Fundamentals of Data Visualization 1/3
2019년, 데이터의 디귿도 모르지만 데이터 시각화에 빠져있을때였다. 기회가 돼 T아카데미에서 여는 파이썬 데이터 시각화 강의를 보러갔고, 강사 이수진님이 강추해주셔서 이 책 Fundamentals of Data
yiyudesign.tistory.com
'dataVisualization' 카테고리의 다른 글
| 책 '모두의 SQL' (0) | 2021.09.25 |
|---|---|
| viz to dataframe 9월 3째주 (0) | 2021.09.24 |
| 데이터와 차트 매핑하기 (1): 비교할 때 (0) | 2021.09.17 |
| 데이터 시각화를 연마하는 두가지 방법 (0) | 2021.09.16 |
| [데이터모델링] PK와 UK의 차이 (Primary Key vs. Unique Key) (0) | 2021.09.12 |



댓글